数据驱动测试用例设计最佳实践
什么是数据驱动?
数据驱动是一种测试设计方法,通过数据来驱动测试用例的执行。在 AsyncTest 中,你可以通过配置数据源的方式,让同一个测试用例在不同数据下执行多次,从而覆盖更多的测试场景。
AsyncTest 提供了两种数据源:
| 数据源类型 | 作用 | 典型用途 |
|---|---|---|
| 全局数据源 | 提供测试生命周期中较为固定的基础数据 | 账号信息、域名配置、公共参数等 |
| 用例数据源 | 驱动测试用例执行的变化数据 | 测试场景的输入参数、预期结果等 |
全局数据源 vs 用例数据源
全局数据源
全局数据源的目的是为了提供在测试用例生命周期中所用到的 较为固定的数据配置。
它的作用不是驱动你的用例,而是 补齐在这个过程中依赖的基础数据。
虽然这样听起来很拗口,但它确实和用例数据源在概念上有着很大的不同:
- 全局数据源是数据驱动的 补充
- 它在配置层面让你的基础数据能够动态化
用例数据源
用例数据源是真正用于 驱动测试用例执行 的数据,它包含了不同测试场景下的输入参数和预期结果。
实战案例:查询订单接口测试
让我们通过一个标准的 Web 接口测试流程来理解两种数据源的区别。
测试目标
测试 查询订单接口 的功能
测试流程
- 登录用户
- 查询订单
数据分析
让我们拆解一下需要准备的数据:
登录接口需要:
- 账号
- 密码
- 域名
查询订单接口需要:
- 域名
- 身份验证 Token
- 查询条件(订单名称、订单号、分页信息等)
如何区分数据源类型?
关键问题:这些数据是否与测试驱动相关?
这是一个较为模糊的概念,但它始终和你的 测试目的 相关。
在当前场景下,我们的目的是 测试查询订单接口,让我们看看三个测试场景:
用例场景 1:按订单号查询
- 设置登录账号为:
sheldon - 设置登录密码为:
sheldon123 - 发送登录接口,获取 token
- 设置订单号为:
order123456 - 设置订单名称为:空
- 设置分页为:
1 - 发送查询订单接口
- 校验结果,第一条订单号是否为:
order123456
用例场景 2:按订单名称查询
- 设置登录账号为:
sheldon - 设置登录密码为:
sheldon123 - 发送登录接口,获取 token
- 设置订单号为:空
- 设置订单名称为:
测试订单123 - 设置分页为:
1 - 发送查询订单接口
- 校验结果,第一条订单名称是否为:
测试订单123
用例场景 3:查询第二页数据
- 设置登录账号为:
sheldon - 设置登录密码为:
sheldon123 - 发送登录接口,获取 token
- 设置订单号为:空
- 设置订单名称为:空
- 设置分页为:
2 - 发送查询订单接口
- 校验结果,是否存在数据
数据源设计
观察上述三个测试场景,我们发现:
- 账号信息(
sheldon/sheldon123)在所有场景中都是固定的 - 查询条件(订单号、订单名称、分页)在不同场景中是变化的
因此,我们可以这样设计数据:
全局数据源(账号信息)
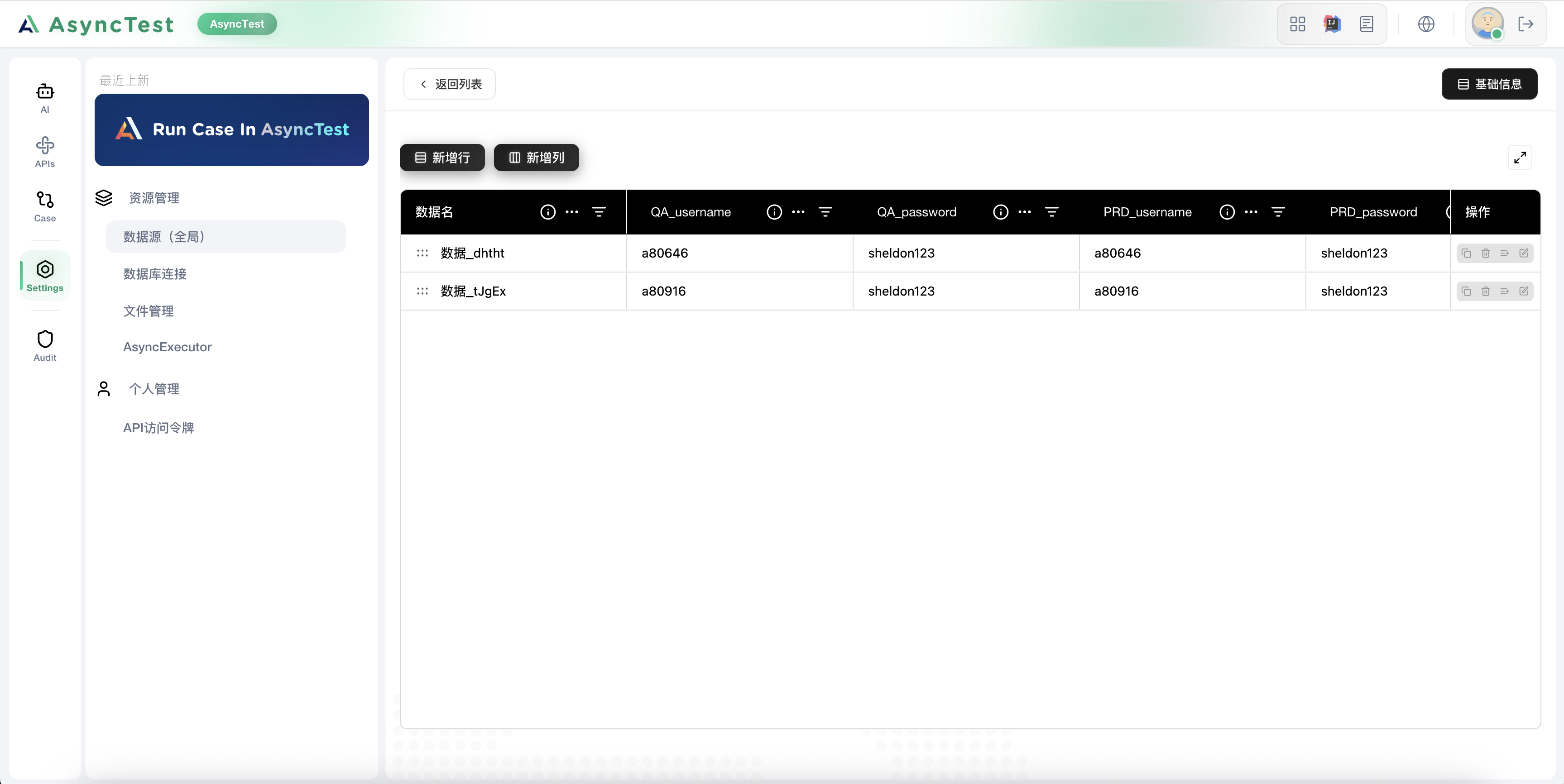
| account_index | QA_username | QA_password | PRD_username | PRD_password |
|---|---|---|---|---|
| 基础自动化 | sheldon | sheldon123 | sheldon_prd | prd_pass123 |
用例数据源(查询条件)
| 场景编号 | 订单号 | 订单名称 | 分页 | 预期结果 |
|---|---|---|---|---|
| 1 | order123456 | 空 | 1 | order123456 |
| 2 | 空 | 测试订单123 | 1 | 测试订单123 |
| 3 | 空 | 空 | 2 | 存在数据 |
判断标准
是否与测试驱动相关?
- 如果数据在不同测试场景中 保持不变,且与测试目的无关 → 全局数据源
- 如果数据在不同测试场景中 需要变化,用于驱动测试执行 → 用例数据源
注意: 这个判断标准与你的测试目的紧密相关。
例如,如果你的测试目的是 测试不同账号下查询订单接口的结果差异,那么账号信息就应该放在用例数据源中,因为它此时是驱动测试的关键数据。
多环境处理最佳实践
在不同环境下,账号信息通常是不同的。如何优雅地处理这个问题?
方案:通过自定义脚本动态选择
账号信息依旧放在全局数据源中,但通过不同的字段名来区分不同环境:
| account_index | QA_username | QA_password | PRD_username | PRD_password |
|---|---|---|---|---|
| 基础自动化 | sheldon_qa | qa_pass123 | sheldon_prd | prd_pass123 |
| 性能测试 | perf_user | perf_pass | perf_user_prd | perf_prd_pass |
在登录用例中编写脚本
# 获取全局数据源
global_data_source = at.get_source
# 根据 account_index 获取账号信息
account_info = global_data_source.query_rows("account_index", "基础自动化", return_index=0)
# 根据当前环境选择对应的账号
if at.env_name == '测试环境':
at.temp.set('username', account_info["QA_username"])
at.temp.set('password', account_info["QA_password"])
elif at.env_name == '生产环境':
at.temp.set('username', account_info["PRD_username"])
at.temp.set('password', account_info["PRD_password"])优化:使用 account_index 索引
通过增加 account_index 字段,我们可以避免在代码中硬编码账号信息,让数据配置更加灵活。
优势:
- 当需要切换账号时,只需修改脚本中的
account_index值 - 可以在全局数据源中维护多套账号信息
- 代码更加清晰,易于维护
OK,现在我们已经将所有的前置知识了解清楚了,下面展示完整的流程示例
完整流程示例
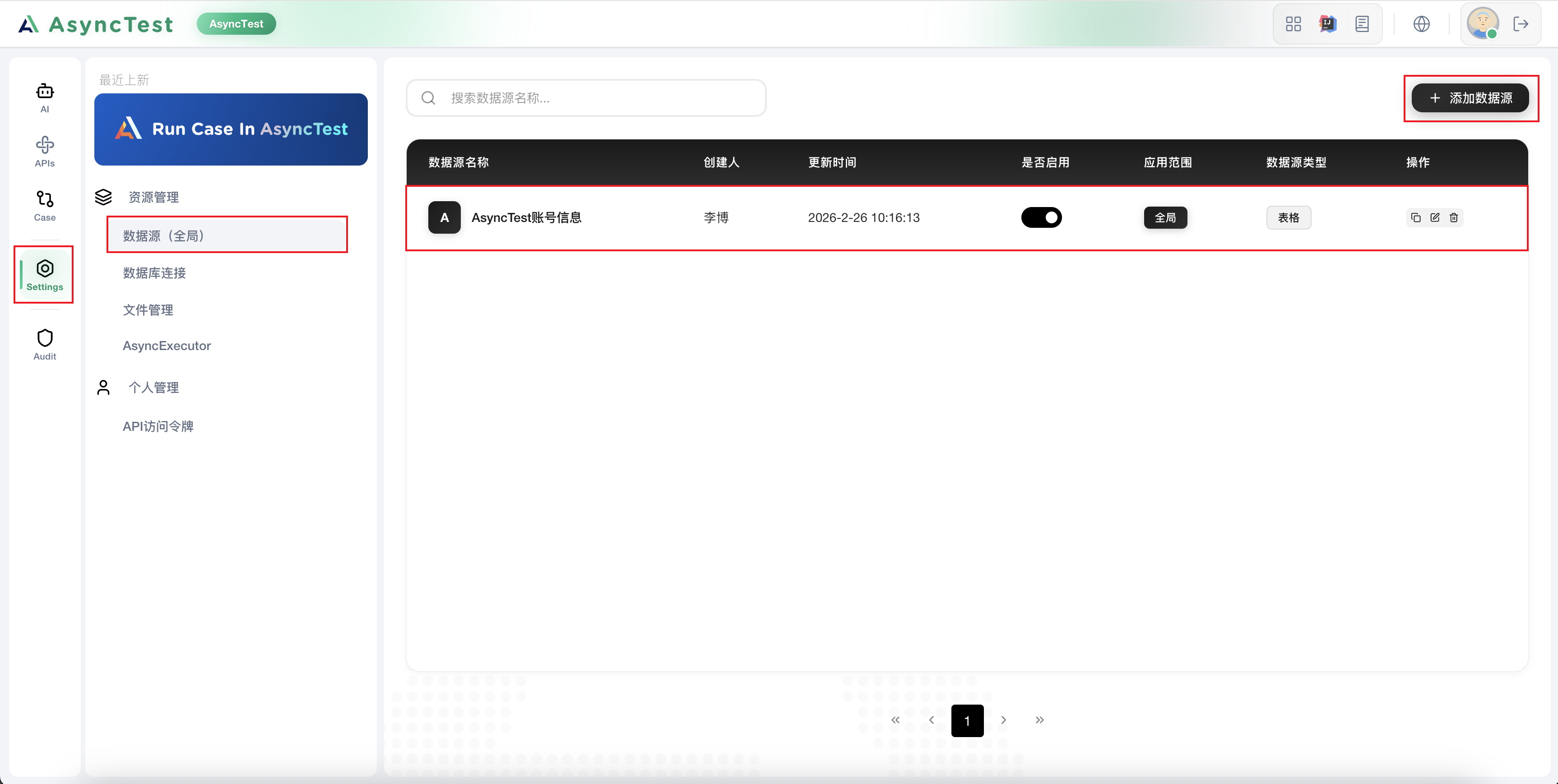
1. 配置全局数据源
在全局数据源中配置账号信息:
2. 创建登录用例
3. 登录用例脚本
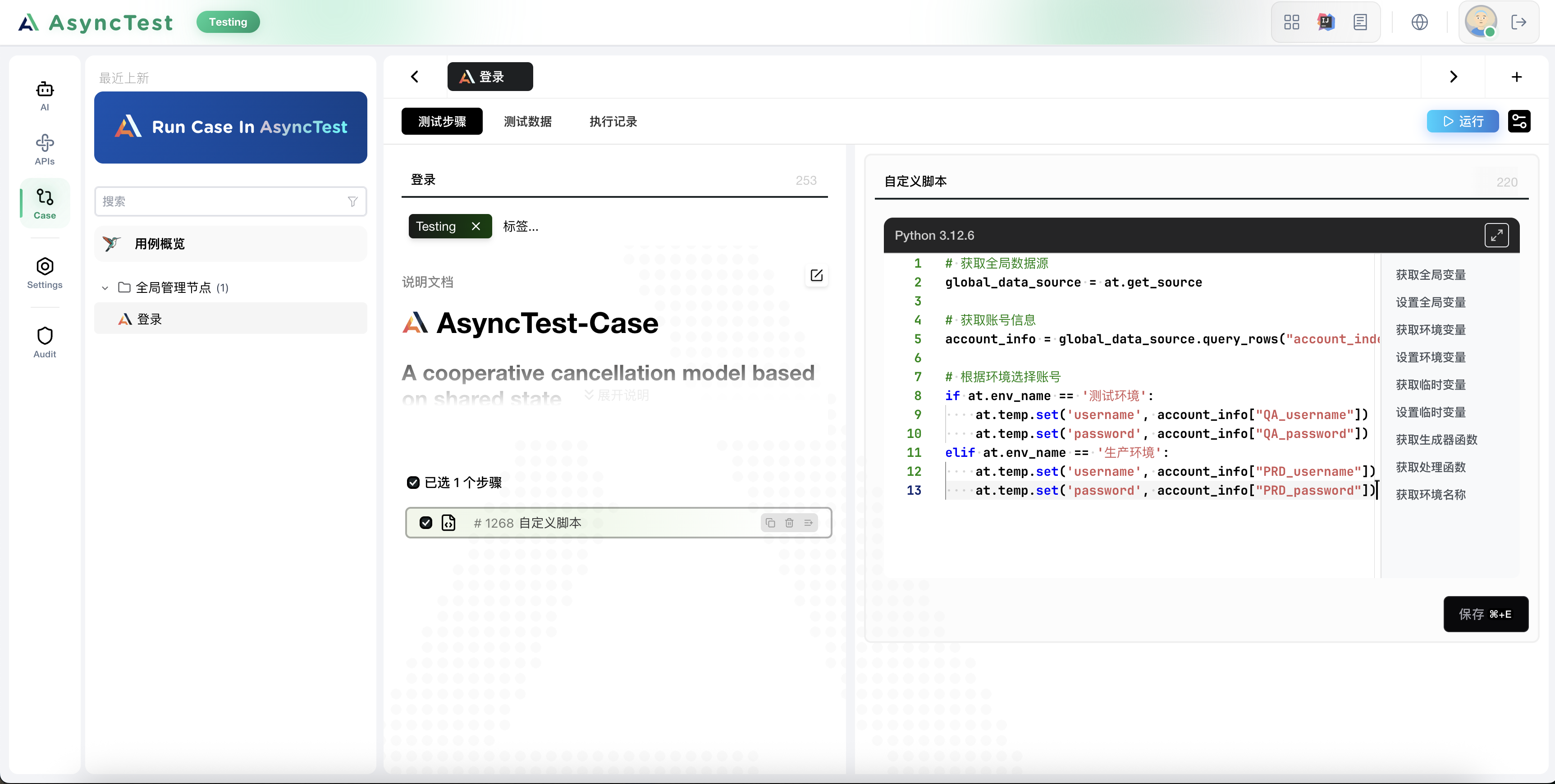
# 获取全局数据源
global_data_source = at.get_source
# 获取账号信息
account_info = global_data_source.query_rows("account_index", "基础自动化", return_index=0)
# 根据环境选择账号
if at.env_name == '测试环境':
at.temp.set('username', account_info["QA_username"])
at.temp.set('password', account_info["QA_password"])
elif at.env_name == '生产环境':
at.temp.set('username', account_info["PRD_username"])
at.temp.set('password', account_info["PRD_password"])3. 创建登录接口,并在用例中引入
创建接口,填写登录接口body
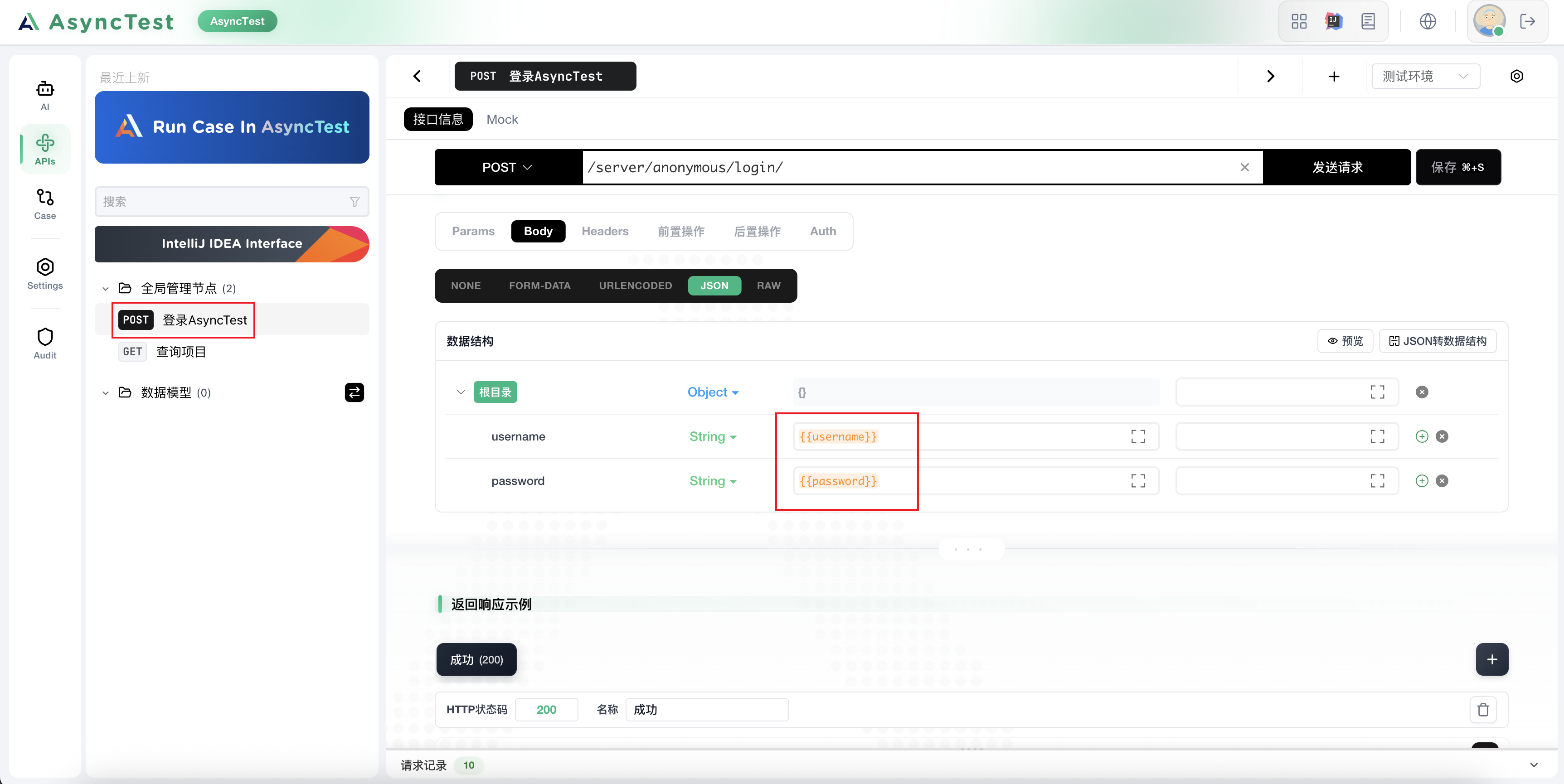
提取登录接口的token
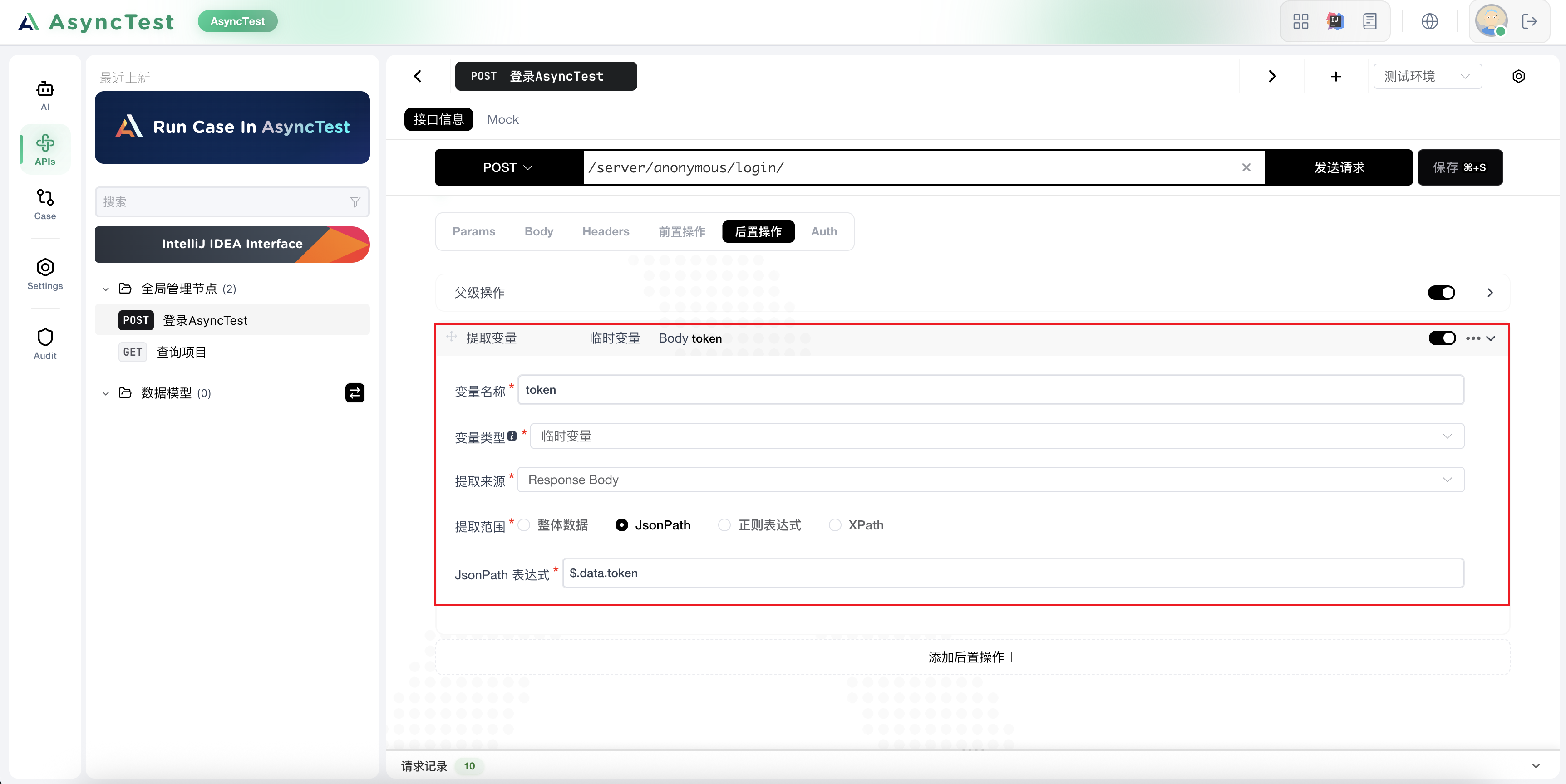
在用例中引入
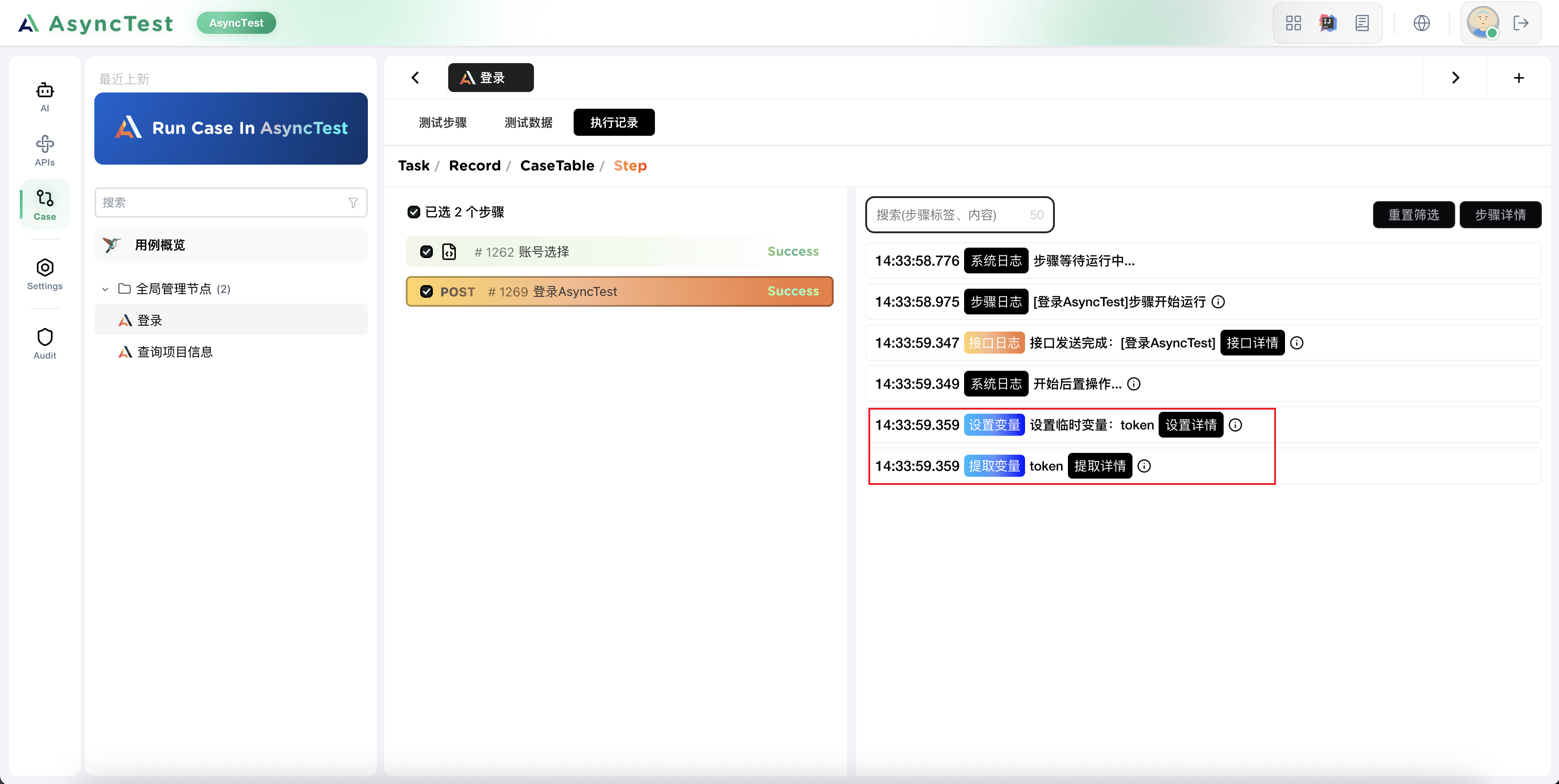
至此我们登录用例已经完成了,尝试下运行得到结果
4. 接下来我们开始完成项目查询接口,并创建测试用例
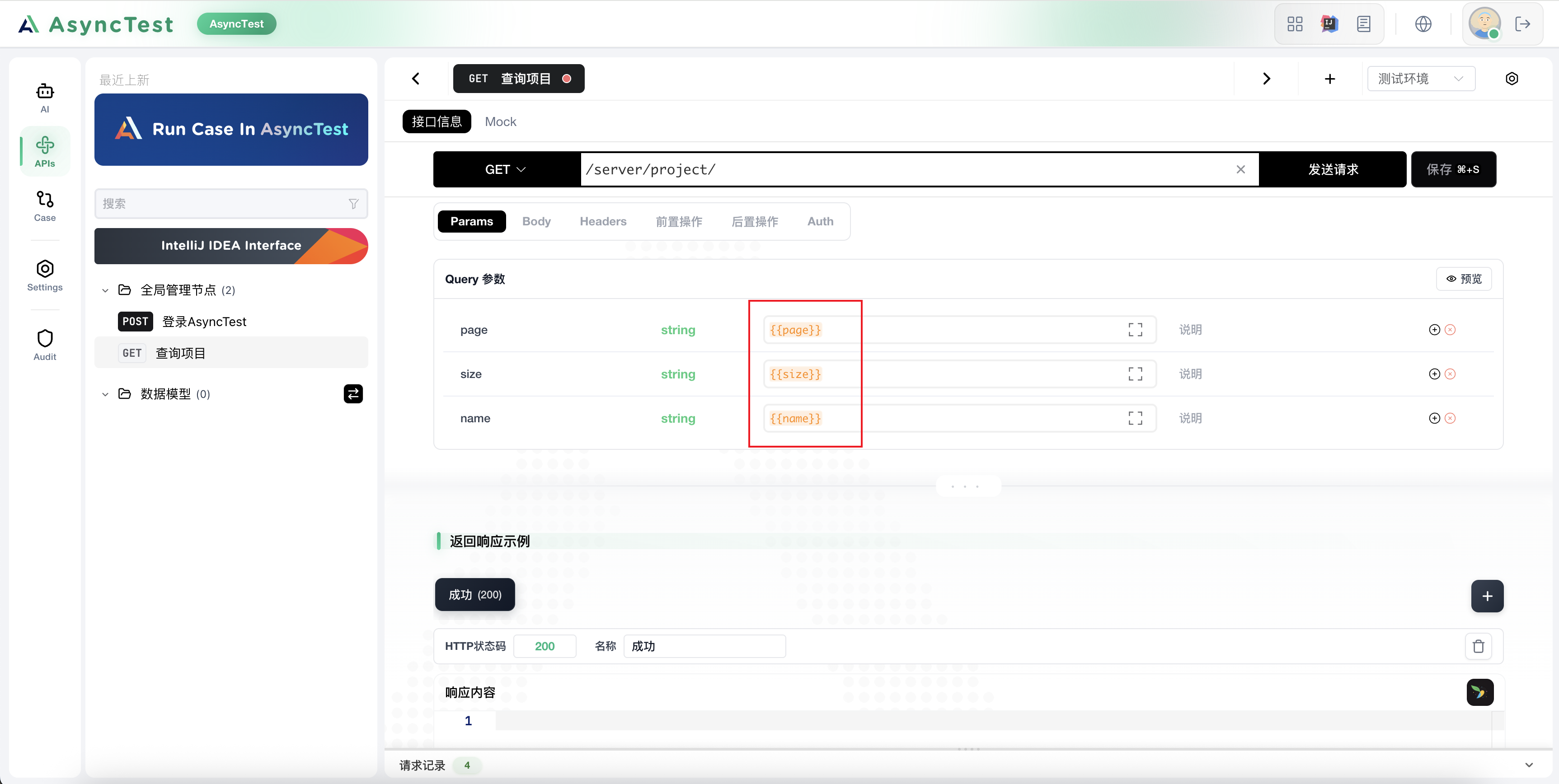
创建项目查询接口
此处我们将 page size name 都给参数化了,后续我们将创建用例数据集来进行驱动它
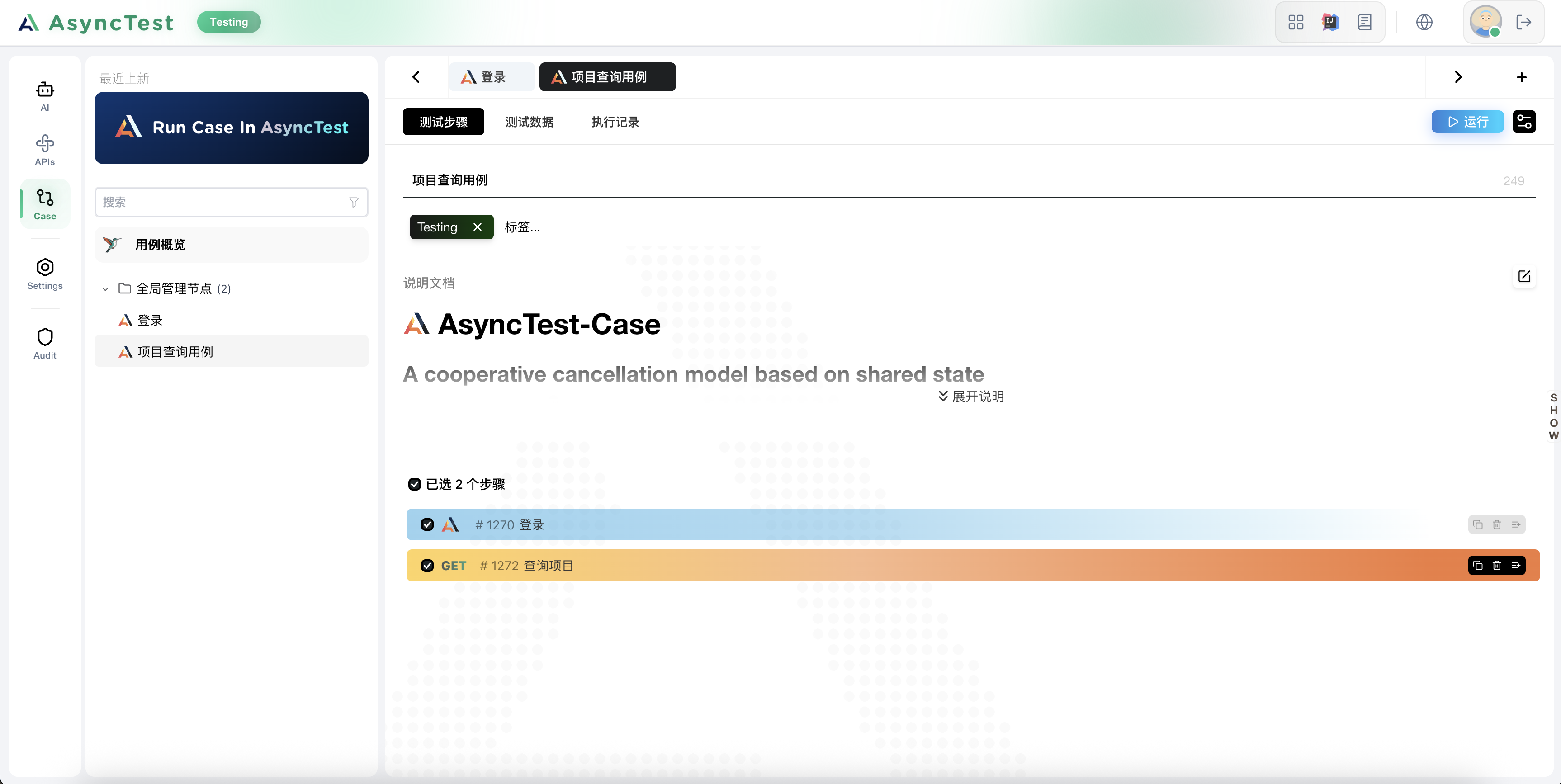
回到用例,我们先引入登录用例和查询项目接口
OK,我们现在去创建用例数据源,来这个数据源来驱动我们的用例
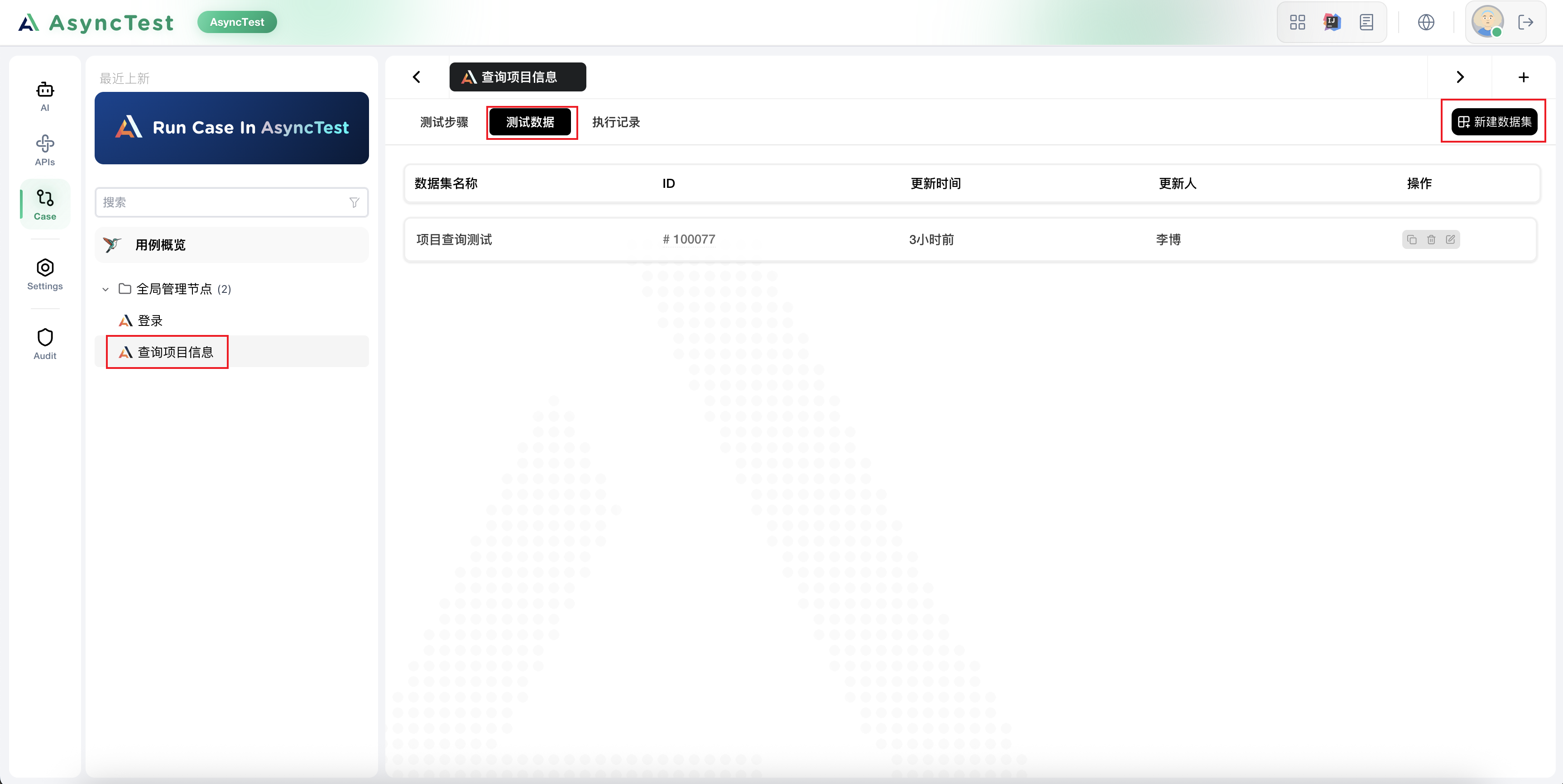
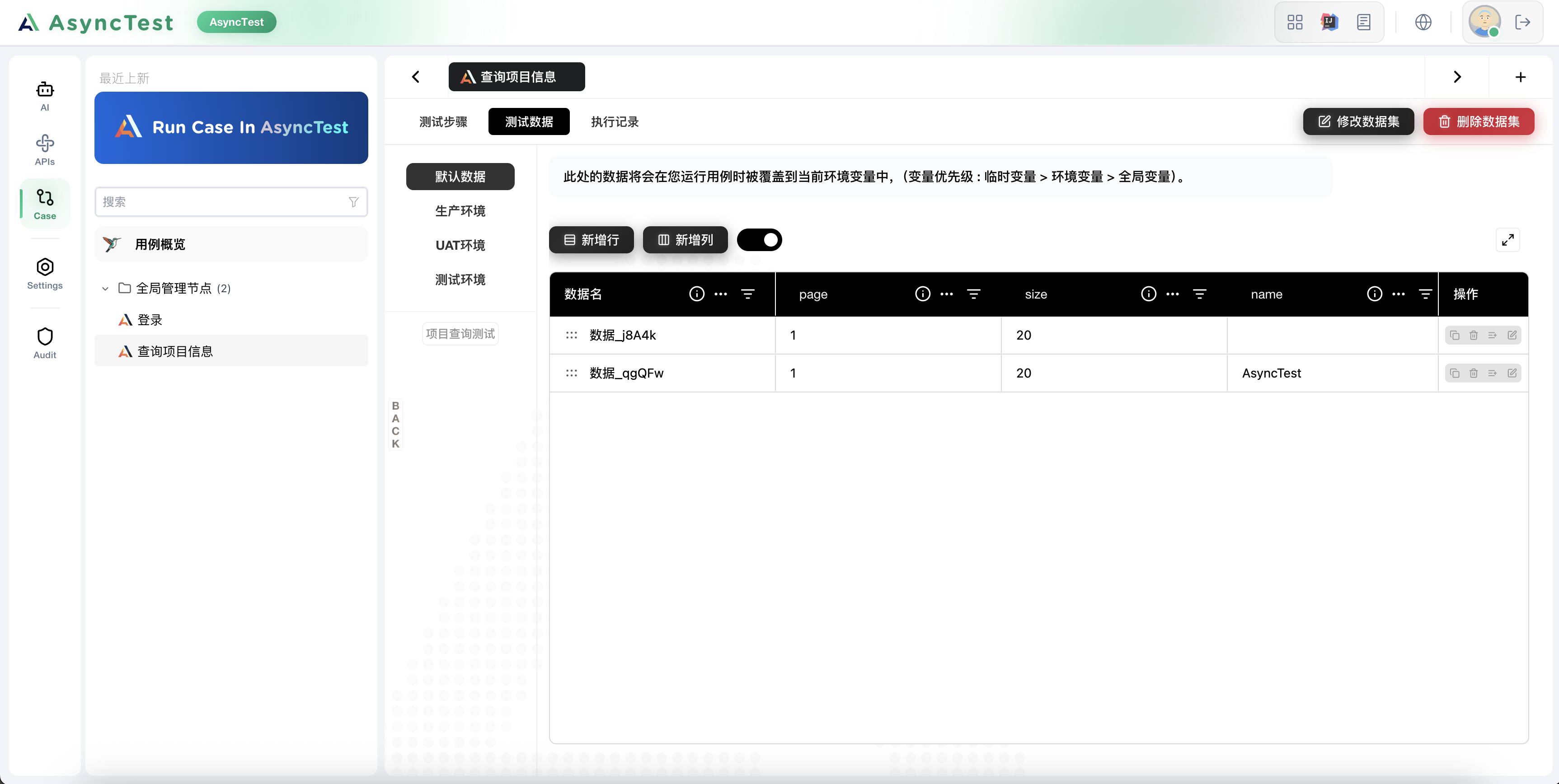
| page | size | name | assertion_index |
|---|---|---|---|
| 1 | 20 | 1 | |
| 1 | 20 | AsyncTest | AsyncTest |
接下来,在用例中绑定这个数据驱动源
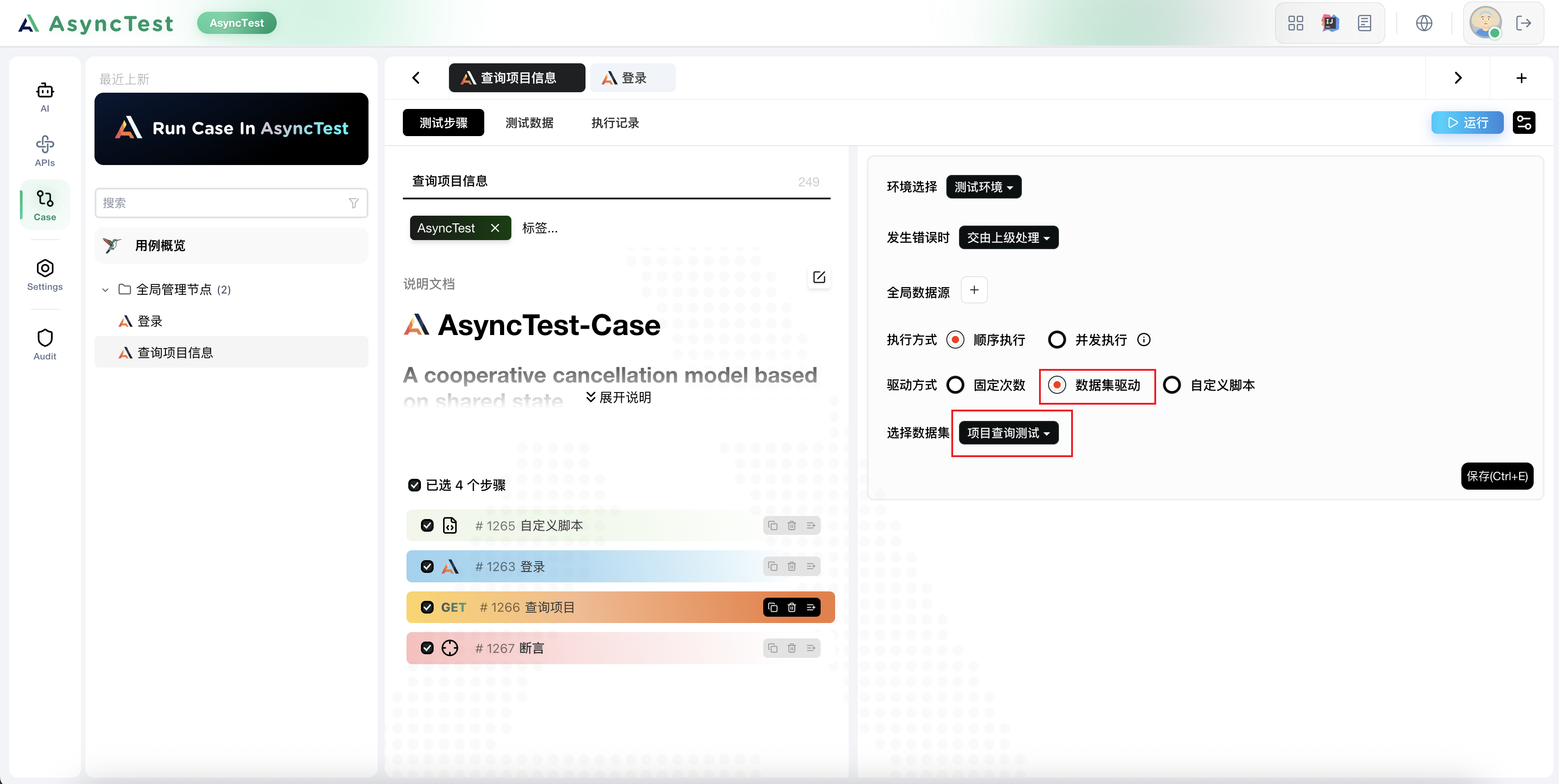
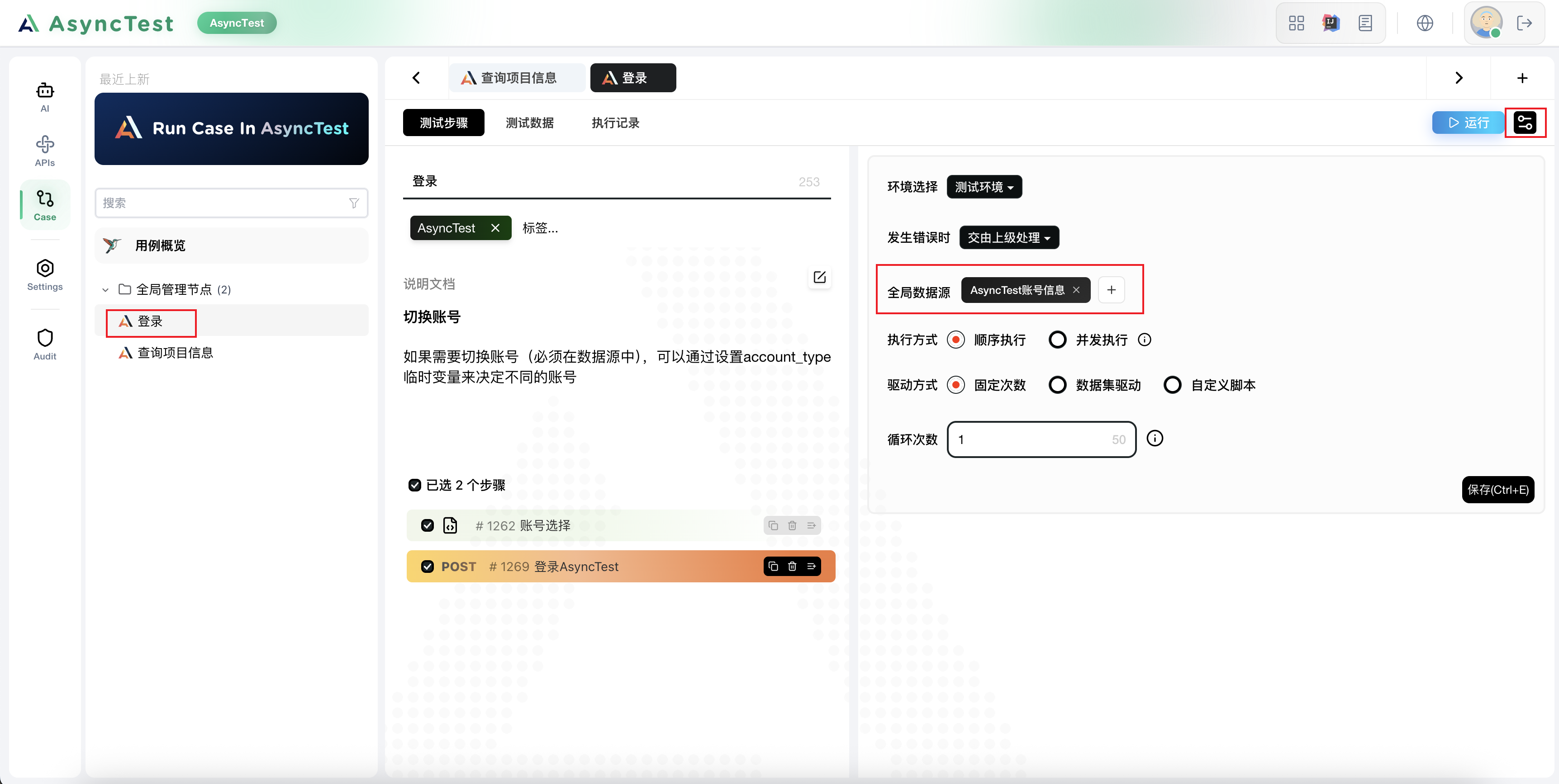
别忘了,去登录用例中,将全局数据源绑定上去
OK,我们再编写一个动态的断言步骤,来进行断言,这个断言脚本完全是通过用例数据源的内容进行控制的
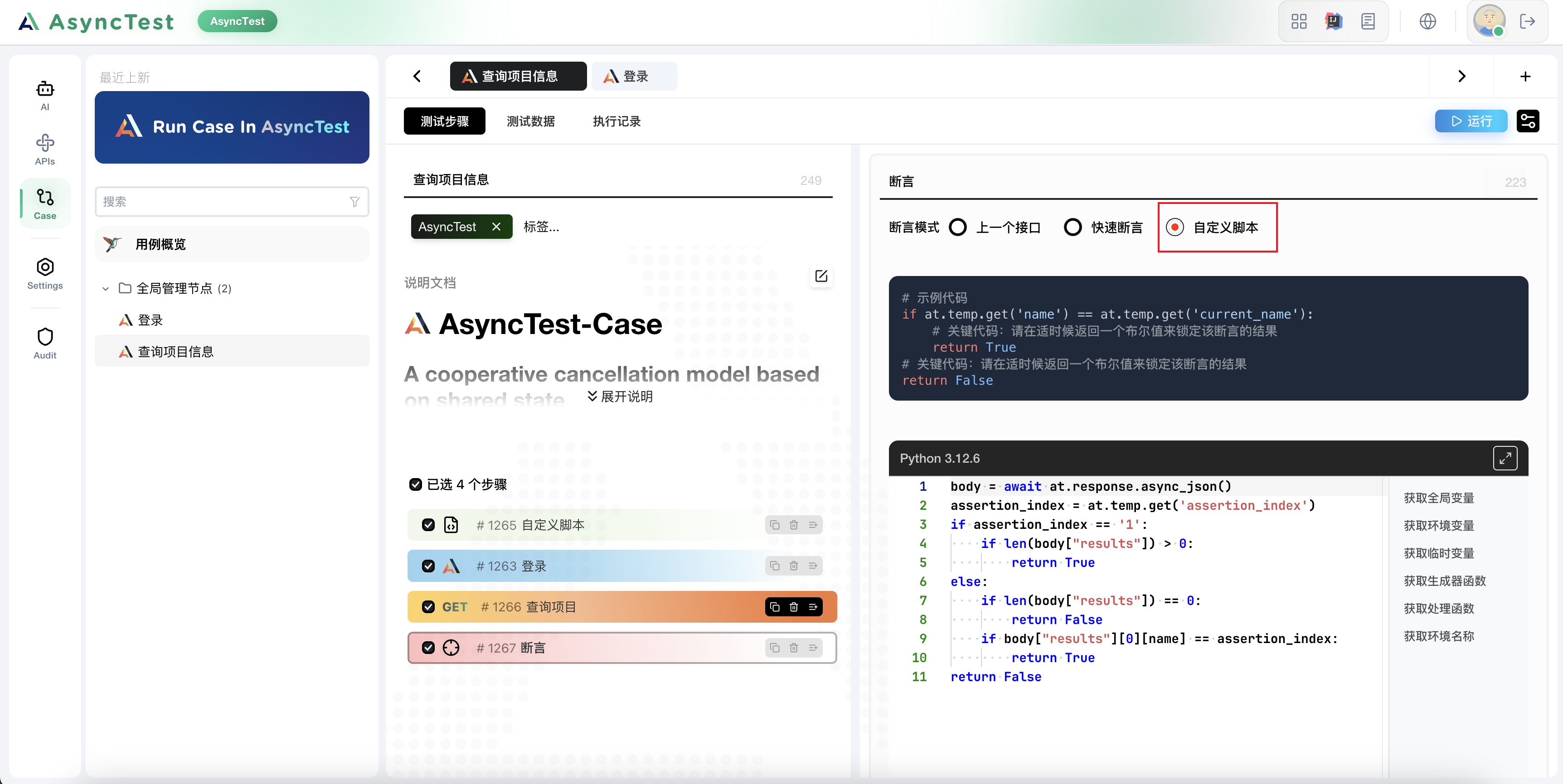
body = await at.response.async_json()
assertion_index = at.temp.get('assertion_index')
if assertion_index == '1':
if len(body["results"]) > 0:
return True
else:
if len(body["results"]) == 0:
return False
if body["results"][0][name] == assertion_index:
return True
return False但是现在我们的登录用例写死了 基础自动化 这套账号,这个是我们不希望的,我们希望在不同的用例中引入登录用例的时候再去决定使用哪套账号来进行登录
所以我们去登录用例中,修改一下脚本,通过一个临时变量来决定后续使用哪套账号进行登录
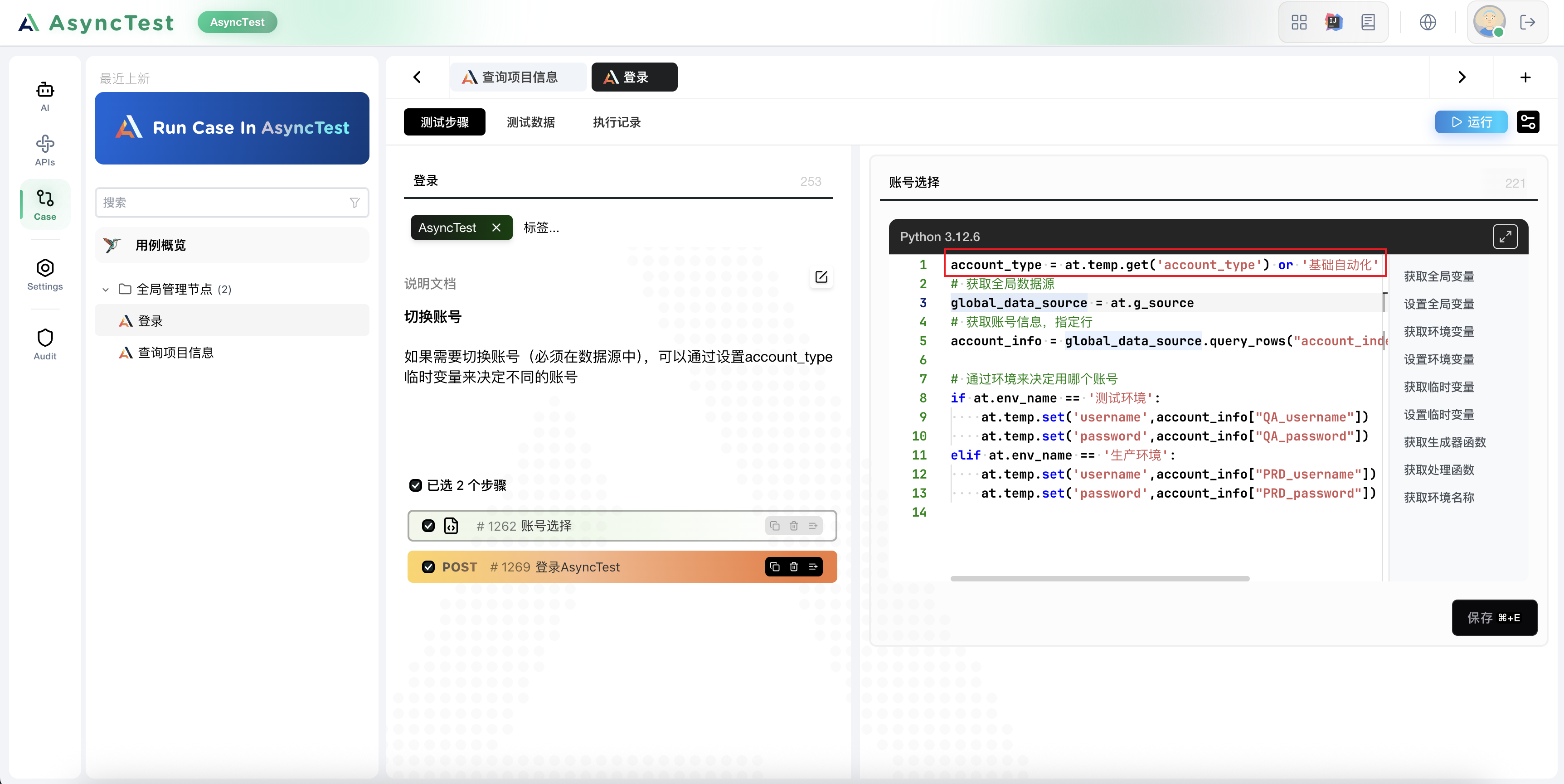
我们最终的 登录用例 中的选择账号的脚本:
account_type = at.temp.get('account_type') or '基础自动化'
# 获取全局数据源
global_data_source = at.g_source
# 获取账号信息,指定行
account_info = global_data_source.query_rows("account_index", account_type)[0]
# 通过环境来决定用哪个账号
if at.env_name == '测试环境':
at.temp.set('username',account_info["QA_username"])
at.temp.set('password',account_info["QA_password"])
elif at.env_name == '生产环境':
at.temp.set('username',account_info["PRD_username"])
at.temp.set('password',account_info["PRD_password"])现在我们就可以在项目查询用例的登录用例之前,通过修改account_type临时变量来决定用哪套账号了
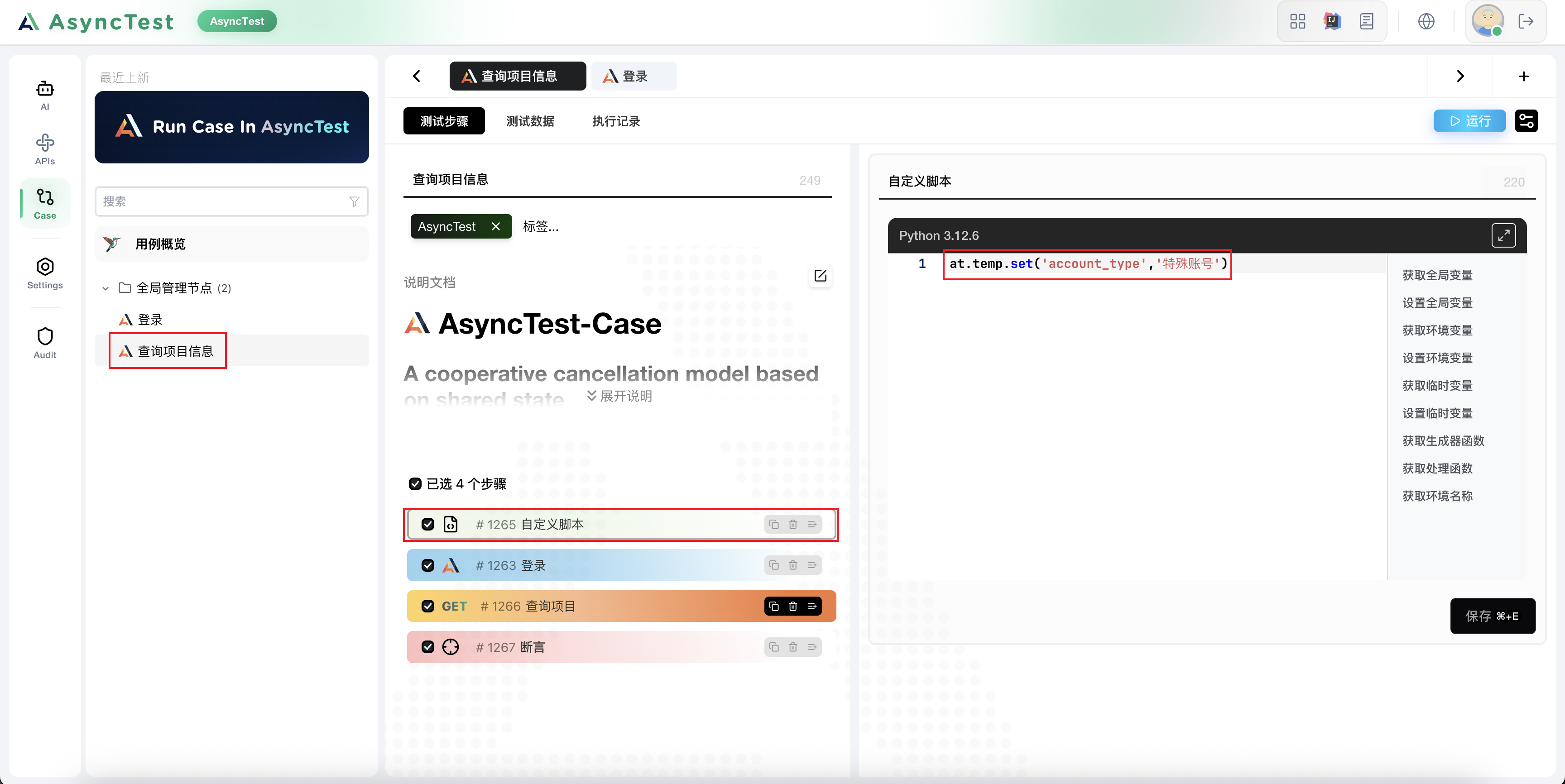
我们这里选择了特殊账号,其实就是全局数据源中的这套账号
至此,我们的最佳实践就完成了
1、我们通过一套全局数据源来保证我们的基础数据
2、我们通过脚本的方式动态的选择了账号,而且还可以适应于不同的环境
3、我们的接口基本上仅做了参数化的操作,其他操作都显式的写在了用例中
4、我们通过用例数据集的方式驱动了我们的 查询项目信息 的用例
5、最后我们也同时通过数据驱动的方式进行了断言
6、未来,我们仅需要改变数据源就可以修改我们的基础数据和数据驱动了
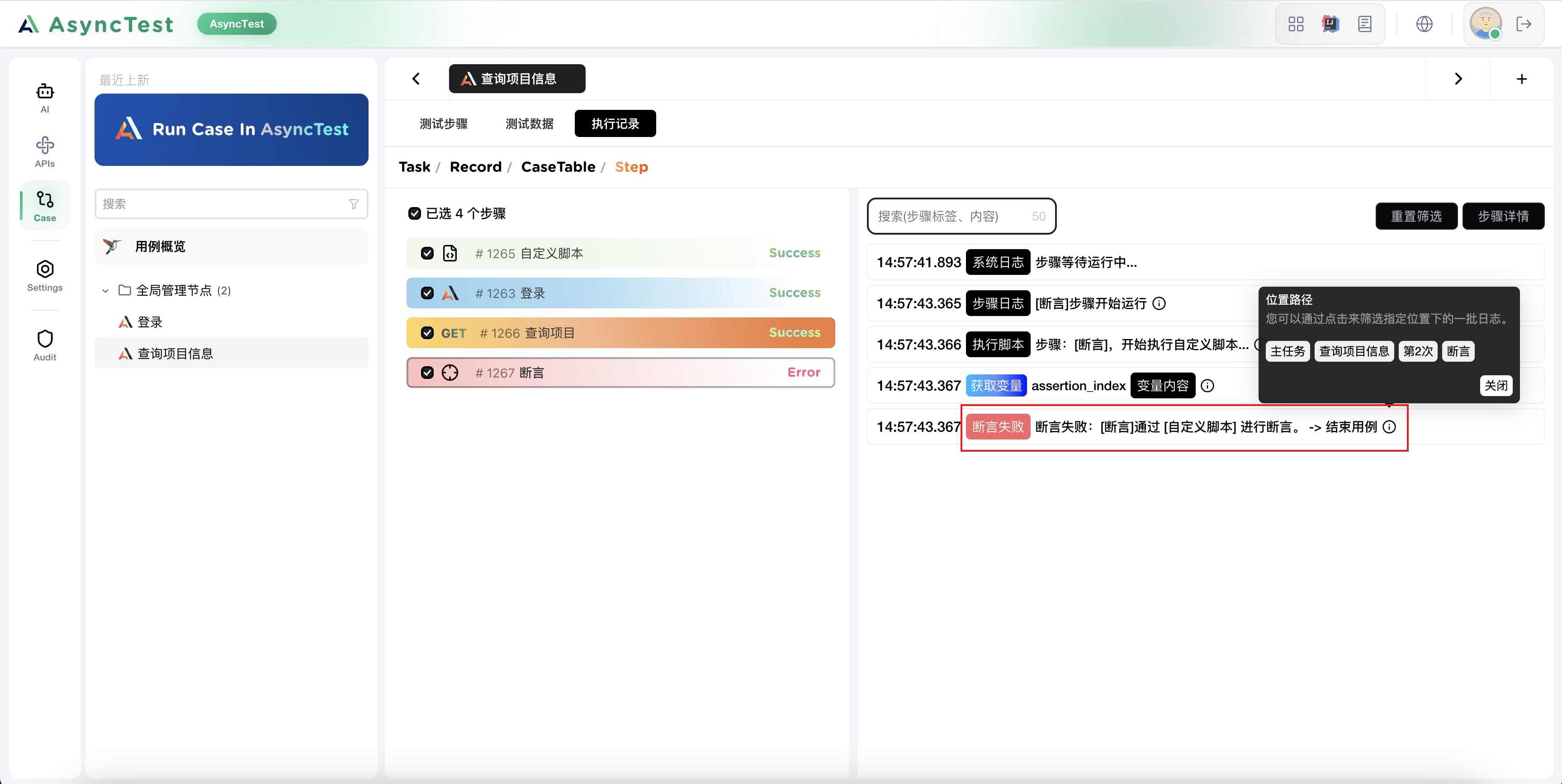
来看看执行结果吧:
发现了一个错误?
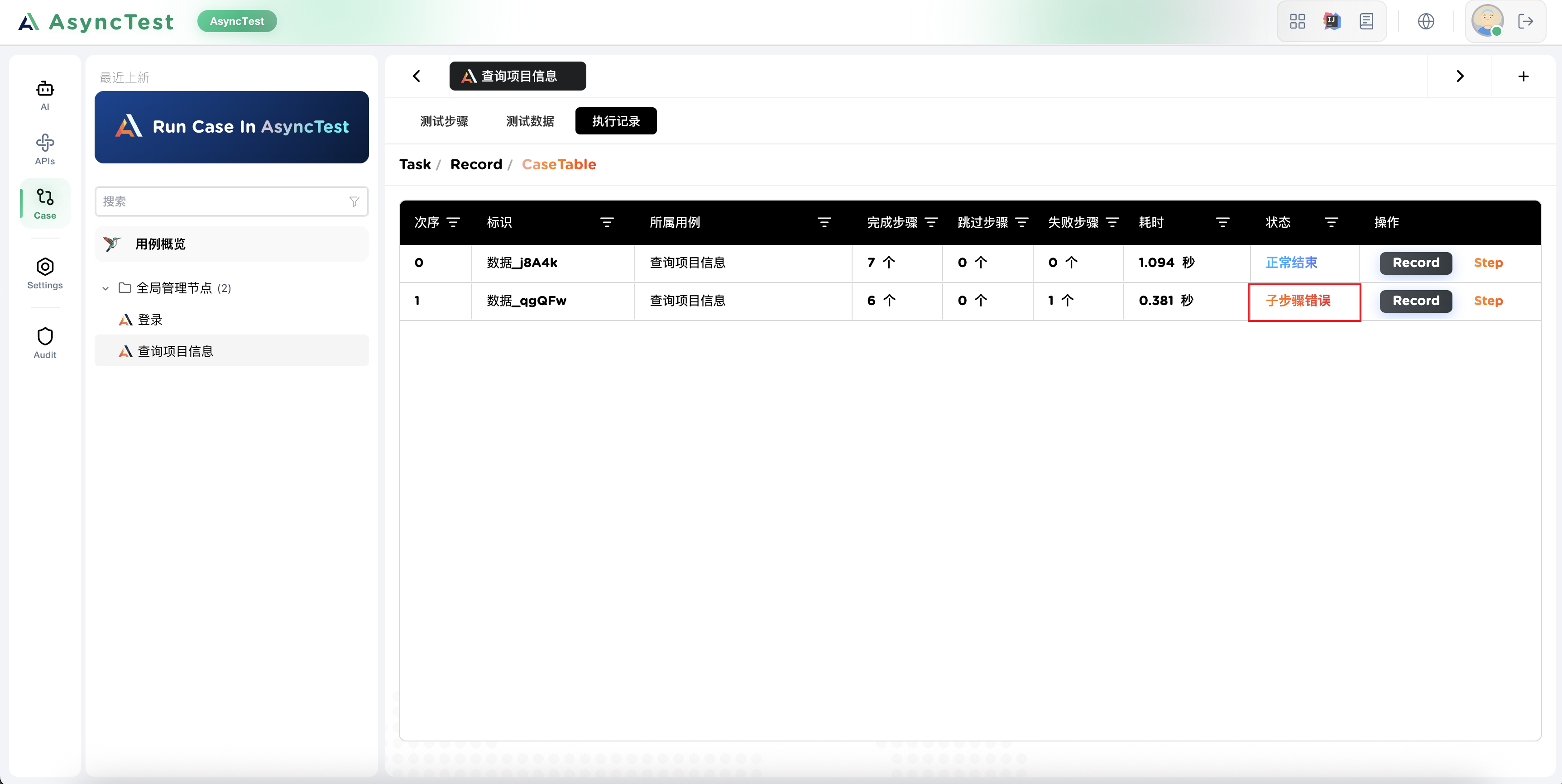
断言错误了,确实,这个接口存在问题